Chinese want to develop scientific AI bots infused with prior knowledge
AI doesn't know anything about physics right now
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article

Read the affiliate disclosure page to find out how can you help Windows Report effortlessly and without spending any money. Read more

Creating scientific AI bots is nothing new. Many researchers worldwide have programmed their own science AI bots to resolve specific tasks in chemistry, biology, physics, and more. However, a new study published in the Hong Kong Polytechnic University journal delivers another approach to creating such bots by infusing them with prior knowledge in the areas where they are needed.
In other words, the Chinese will train the LLMs to become AI scientists in their field of expertise by teaching them some advanced rules, just instructing students before giving them tasks.
AI bots don’t know anything about physics, yet
Although we got used to the fast-paced development of AI, we still feel amazed by how Sora AI can create elaborate video clips just from text input. Yet, the text-to-video LLM doesn’t have the slightest idea about the laws of physics. It doesn’t know how to extract a piece of cookie from the image after someone bites it or the direction in which the flames of candles should lean when someone blows at them in a clip.
LLMs are traditionally trained using localized data and inputs and don’t start from ground rules in mathematics or physics. Copilot doesn’t even know how to count some objects in a generated image. We gave it hundreds of tests to generate a fixed number of a particular object, and the bot failed at determining the number of items. However, it will respond flawlessly if you ask it to solve a simple math equation.
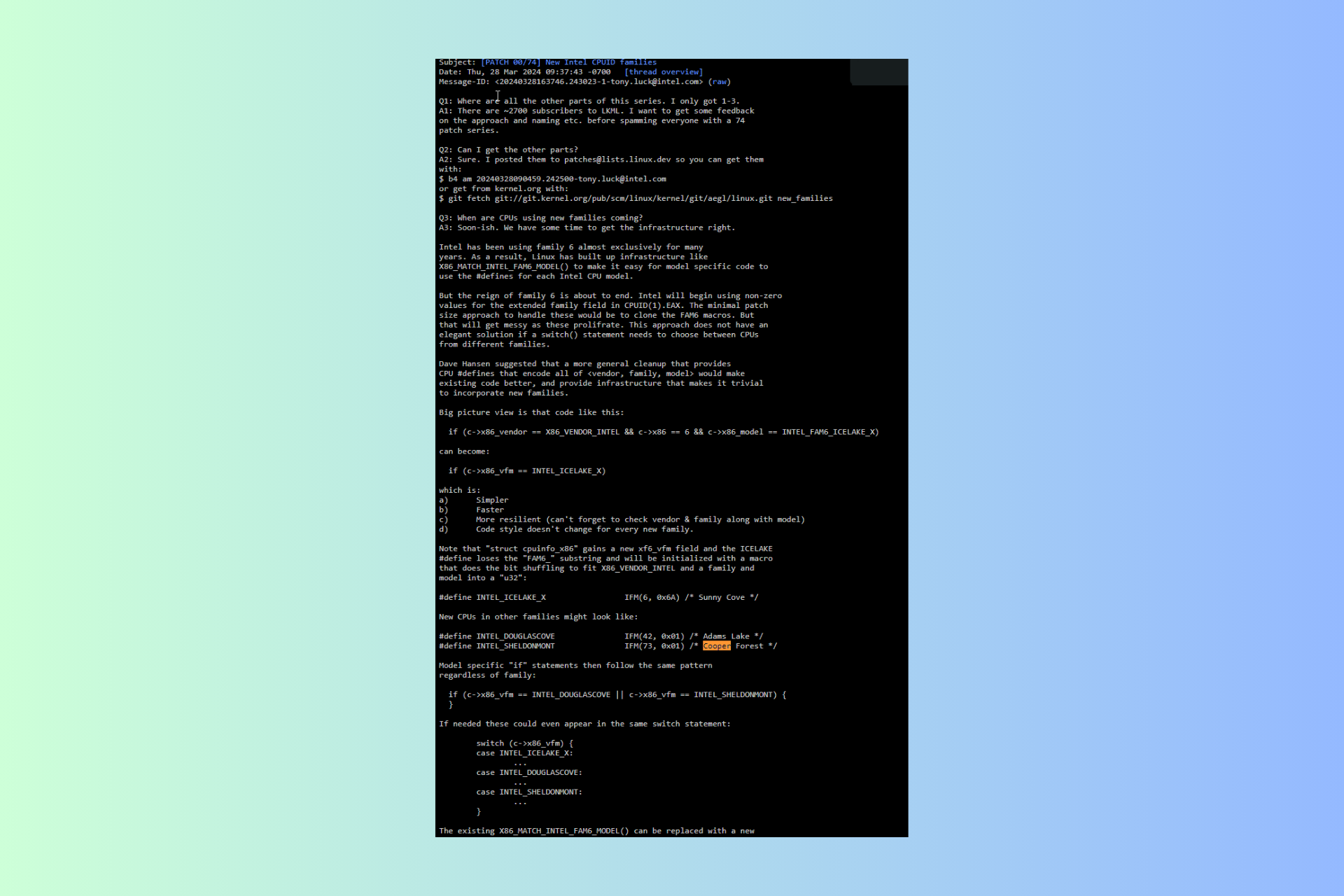
The Chinese scientists believe that the AI bots will deliver more accurate results by creating an informed machine learning model through base knowledge training. However, they admit it takes work to establish which functional relationships, equations, and logic to include in the training. They found out that inserting too many rules would crash the LLM.
Embedding human knowledge into AI models has the potential to improve their efficiency and ability to make inferences. Still, the question is how to balance the influence of data and knowledge. Our framework can be employed to evaluate different expertise and rules to enhance the predictive capability of deep learning models.
Xu Hao, first author and researcher at Peking University
According to the paper, the Chinese created a framework that assesses rule importance by examining how certain rules or combinations affect the predictive accuracy of the LLM.
The researchers tested their framework to predict a chemistry experiment’s results and optimize a model for solving multivariate equations, and the output was a success.
However, there is an inherent problem with this type of training. During the study, the scientists discovered that if they added more data to the model, the general rules they applied became more important than the local rules. This is an issue because biology and chemistry often don’t have readily available general rules akin to governing equations.
The scientists are creating an open source plugin tool for developers to advance this training model further.